Introduction to Embeddings
Embeddings are at the heart of how modern chatbots interpret text. Essentially, embeddings are numerical representations of words, phrases, or even sentences, capturing semantic relationships in a dense, vectorized format. This enables chatbots to "understand" and process language in a way that’s mathematically grounded, moving beyond simple keyword matching.
For instance, the words "dog" and "puppy" are closely related in meaning. In an embedding space, these words are represented as vectors that are closer together, while "dog" and "car" would be farther apart.
How Embeddings Work: Dimensionality and Context
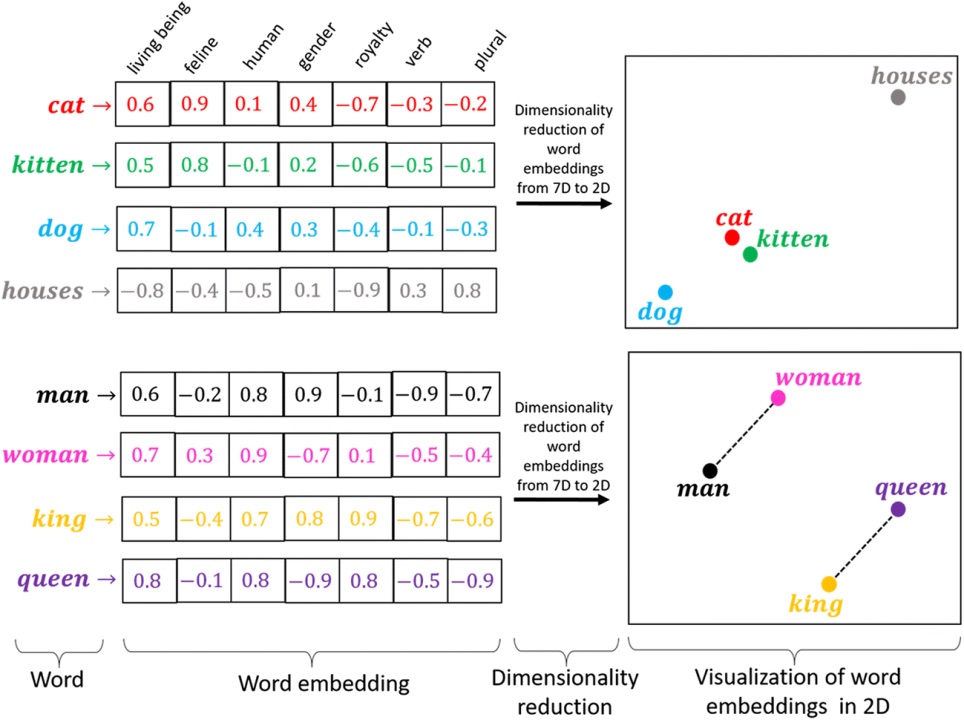
Embeddings reduce high-dimensional linguistic data into lower-dimensional, contextually meaningful vectors. Unlike older techniques like one-hot encoding, which treat words as independent entities, embeddings use dense vectors to represent relationships and context. For example, using embeddings, "king" and "queen" share a close vector space due to their semantic similarity, while “man” and “woman” similarly capture gender-related analogies.
Example: Capturing Context Embeddings like Word2Vec or GloVe are trained on vast amounts of text data, capturing how words co-occur. For example, in Word2Vec, "bank" might appear in contexts like "bank loan" or "river bank." The model learns that "bank" has different meanings depending on its neighbors.
Contextualized Embeddings in LLMs
Advanced language models like BERT and GPT bring another layer to embeddings by using contextualized representations. Here, each word’s embedding is dynamically generated based on the sentence it appears in. This allows chatbots to differentiate between meanings in real-time.
For instance:
- In "deposit money at the bank," "bank" is understood as a financial institution.
- In "walk along the river bank," "bank" is the edge of a river.
This contextualization allows chatbots to generate accurate responses even for ambiguous terms, enhancing their ability to understand nuanced language.
Using Embeddings for Intent Recognition and Response Generation
When a user interacts with a chatbot, embeddings enable the bot to understand the intent behind the input. Suppose a user says, "I need help with a purchase." Embeddings will position this phrase near others like "Can you assist with my order?" indicating a request for assistance. This helps chatbots identify intent accurately, regardless of phrasing.
For response generation, pre-trained embeddings guide the chatbot to generate or retrieve responses that align with the input's meaning. For example, if a user often talks about travel, embeddings can help prioritize travel-related responses, making the conversation feel personalized.
Challenges in Embedding Implementation
While embeddings are powerful, they come with challenges:
- Bias: Since embeddings reflect the training data, they can inherit biases present in that data. Careful dataset curation and regular monitoring are necessary to mitigate this.
- Nuance and Sarcasm: Embeddings may struggle with language nuances, such as sarcasm or idiomatic expressions. Developers often need fallback strategies, like explicit handling for common idioms.
- Computational Demand: Training large-scale models with embeddings is resource-intensive. However, cloud solutions are making it more accessible for developers.
The Future of Chatbots with Embeddings
As embeddings continue to evolve, they are likely to combine with other AI techniques, like symbolic reasoning, to enhance chatbot comprehension. Real-time, adaptive embeddings may soon allow chatbots to improve responses based on interactions dynamically.