
One of HammerAI's standout features is its ability to run powerful language models locally on your hardware. This is achieved thanks to llama.cpp, an efficient implementation of the popular LLaMA (Large Language Model Meta AI) models that can operate without cloud-based servers. In this article, we'll explore how llama.cpp makes HammerAI a privacy-focused, fast, and customizable solution for AI-based chat.
What is llama.cpp?
llama.cpp is a C++ implementation designed to run Meta's LLaMA models directly on consumer hardware. Unlike most AI models that require powerful cloud servers to function, llama.cpp optimizes memory usage and computation to enable local execution on CPUs, GPUs, or specialized hardware like Apple's M1/M2 chips.
For HammerAI users, this means:
- Full privacy: All processing happens on your device, ensuring that no conversations are sent over the internet.
- Offline capabilities: Since it doesn't rely on cloud infrastructure, you can use HammerAI even without an internet connection.
- Improved latency: By eliminating the need to connect to a remote server, responses can be generated almost instantly.
How Does llama.cpp Work?
The llama.cpp framework optimizes LLaMA models to work efficiently with the hardware available on modern devices. Here's a look at how it achieves that:
-
Quantization for Reduced Memory Use
One of the core innovations of llama.cpp is model quantization: a process that reduces the memory footprint of the AI model by approximating some numbers in the model's weights. This allows large language models (LLMs) like LLaMA to run on devices with much less RAM, such as a laptop or even a high-end smartphone.For example, a typical 13 billion parameter LLaMA model might need tens of gigabytes of memory, but after quantization, llama.cpp can reduce this requirement to just 4–8GB, depending on the quantization method.
-
Hardware Acceleration
llama.cpp also takes full advantage of hardware-specific optimizations. It supports:- Nvidia, AMD, Intel GPUs: HammerAI can utilize these to accelerate AI processing, making responses faster and enabling real-time interactions.
- Apple Silicon (M1/M2): On Macs with Apple chips, llama.cpp is optimized to leverage Apple's neural engine, significantly speeding up model inference.
-
Efficient Multithreading
By using C++ for low-level memory management and computation, llama.cpp can distribute the work across multiple CPU or GPU threads. This parallel processing allows HammerAI to generate responses faster than a typical cloud-based model that depends on round-trip latency.
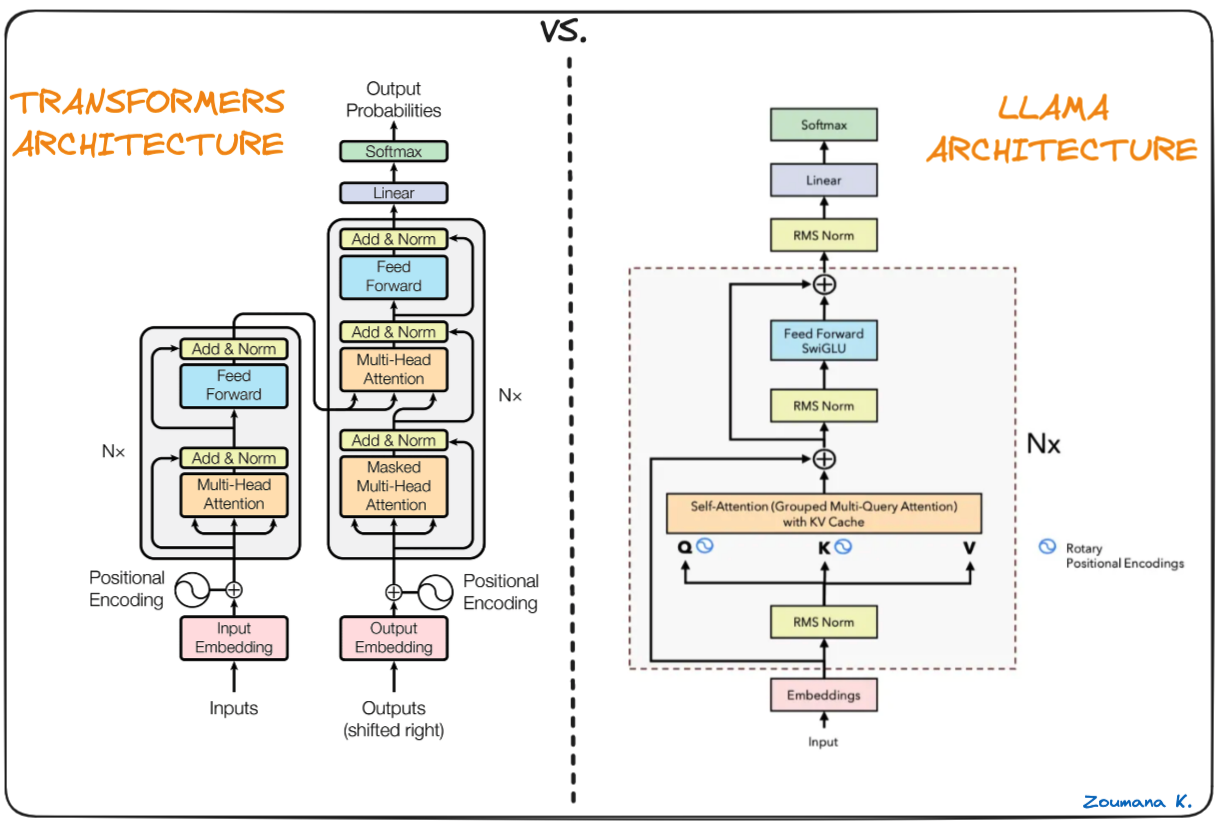
Advantages of Running Models Locally
Running AI models locally, as HammerAI does with llama.cpp, provides several advantages over cloud-based solutions like Crushon.ai or ChatGPT:
- Total Control: Users retain full control over their data since it never leaves their device.
- Customization: HammerAI allows users to import their own models. For example, if you want to fine-tune a LLaMA model for specific tasks, you can do so locally.
- Reduced Costs: There are no cloud usage fees because everything is computed on your hardware.
Use Cases for HammerAI's Local Model Capabilities
Here are a few scenarios where HammerAI's local model capabilities shine:
- Private conversations: Whether you're chatting with an AI for therapy or sensitive data analysis, you can rest assured that your conversations stay private.
- Offline environments: Need an AI assistant while traveling without reliable internet? HammerAI has you covered.
- Custom AI training: Developers and hobbyists can experiment with different models, tuning and testing them directly on their machine without worrying about server limitations or costs.
How to Get Started with llama.cpp in HammerAI
If you're curious about how HammerAI uses llama.cpp under the hood, here's how you can start:
- Download HammerAI: Download the app and install it on your device. It comes with a set of pre-configured models that leverage llama.cpp.
- Run Models on Your GPU: If you have a dedicated GPU, HammerAI will automatically use it for even faster processing.
- Customize Your Models: If you're feeling adventurous, you can import your own models. Just find an Ollama Modelfile and import it directly.
Conclusion
HammerAI's integration with llama.cpp brings the power of large language models directly to your device, ensuring privacy, offline functionality, and faster response times. Whether you're looking for a secure, customizable AI assistant or need to run models in environments with limited connectivity, HammerAI's local-first approach is a game changer.